Transcribe an audio file
This article shows how you can simply transcribe a file using NeuralSpace's VoiceAI platform. Follow along for your preferred method - UI, API or Python SDK, by selecting the appropriate tabs below.
Prerequisites
Make sure to follow Get Started to sign up and have all the necessary pre-requisites.
If you are using the APIs or the SDK, save your API key in a variable called NS_API_KEY before moving ahead. Do this by using the command below
export NS_API_KEY=YOUR_API_KEY
Refer to the Supported Languages page for language codes and supported domains.
Sample Audio Files
You can experiment with the sample audio files in English here and Arabic here.
Start a File Transcription Job
- API
- Python SDK
- UI
Copy and paste the below mentioned curl requeston your terminal to start a transcription using the API. Fill the variables with the appropriate values.
curl --location 'https://voice.neuralspace.ai/api/v1/jobs' \
--header "Authorization: $NS_API_KEY" \
--form 'files=@"{{LOCAL_AUDIO_FILE_PATH}}"' \
--form 'config="{\"file_transcription\":{\"language_id\":\"{{LANG}}\", \"mode\":\"advanced\", \"number_formatting\":\"{{NUMBER_FORMATTING}}\"}}"'
| Variable | Required | Description |
|---|---|---|
| NS_API_KEY | Yes | Your API key from the platform. |
| LOCAL_AUDIO_FILE_PATH | Yes | File path on your local machine of the audio file that you want to transcribe. |
| LANG | No | Language ID corresponding to the source audio file. Refer Language Support to get the language IDs. If no language ID is passed, the language is auto-detected using AI. |
| MODE | Yes | fast or advanced, depending on whether you want higher speed or higher accuracy. Currently, only advanced is supported. |
| NUMBER_FORMATTING | No | digits or words, depending on whether you want the output to have numbers formatted as digits or words. If this argument is not passed, it returns the transcript without any additional formatting. |
Apart from the required configurations that have been passed in the example above, we support more optional configurations as well. Please refer to the API Reference for more details on how to pass them in the request.
For details and examples, check out:
When a request is sent via the curl command above, it returns the details of the job created including its jobId, and error message, if any. An example response is given below.
{
"success": true,
"message": "Job created successfully",
"data": {
"jobId": "281f8662-cdc3-4c76-82d0-e7d14af52c46"
}
}
Make sure you have the neuralspace package installed in your python environment. Follow these steps to install the package using pip and set the environment variable for your API key.
pip install neuralspace
export NS_API_KEY=YOUR_API_KEY
Once you have the package and API key set up, execute the following python code snippet to create a transcription job.
import requests
import neuralspace as ns
filename = 'english_audio_sample.mp3'
# Download the sample audio file
print('Downloading sample audio file...')
resp = requests.get('https://github.com/Neural-Space/neuralspace-examples/raw/main/datasets/transcription/en/english_audio_sample.mp3')
with open(filename, 'wb') as fp:
fp.write(resp.content)
vai = ns.VoiceAI()
# or,
# vai = ns.VoiceAI(api_key='YOUR_API_KEY')
# Setup job configuration
config = {
'file_transcription': {
'language_id': 'en',
'mode': 'advanced',
},
}
# Create a new file transcription job
job_id = vai.transcribe(file=filename, config=config)
print(f'Created job: {job_id}')
| Field | Required | Description |
|---|---|---|
| LANG | Yes | Language ID of the target language for the audio file. Refer Language Support to get the language IDs. |
| MODE | Yes | fast or advanced, depending on whether you want higher speed or higher accuracy. |
| NUMBER_FORMATTING | No | digits or words, depending on whether you want the output to have numbers formatted as digits or words. If this argument is not passed, it returns the transcript without any additional formatting. |
Apart from the required configurations that have been passed in the example above, we support more optional configurations as well. Please refer to the Github repository for more details.
For details and examples, check out:
When a request is sent via the Python script above, it returns the details of the job created including its jobId, and error message, if any. An example response is given below.
Downloading sample audio file...
Created job: 6abe4f35-8220-4981-95c7-3b040d9b86d1
A file transcription job can be created using the UI by simply clicking here or on the File Transcription card on the homepage of the VoiceAI Platform.
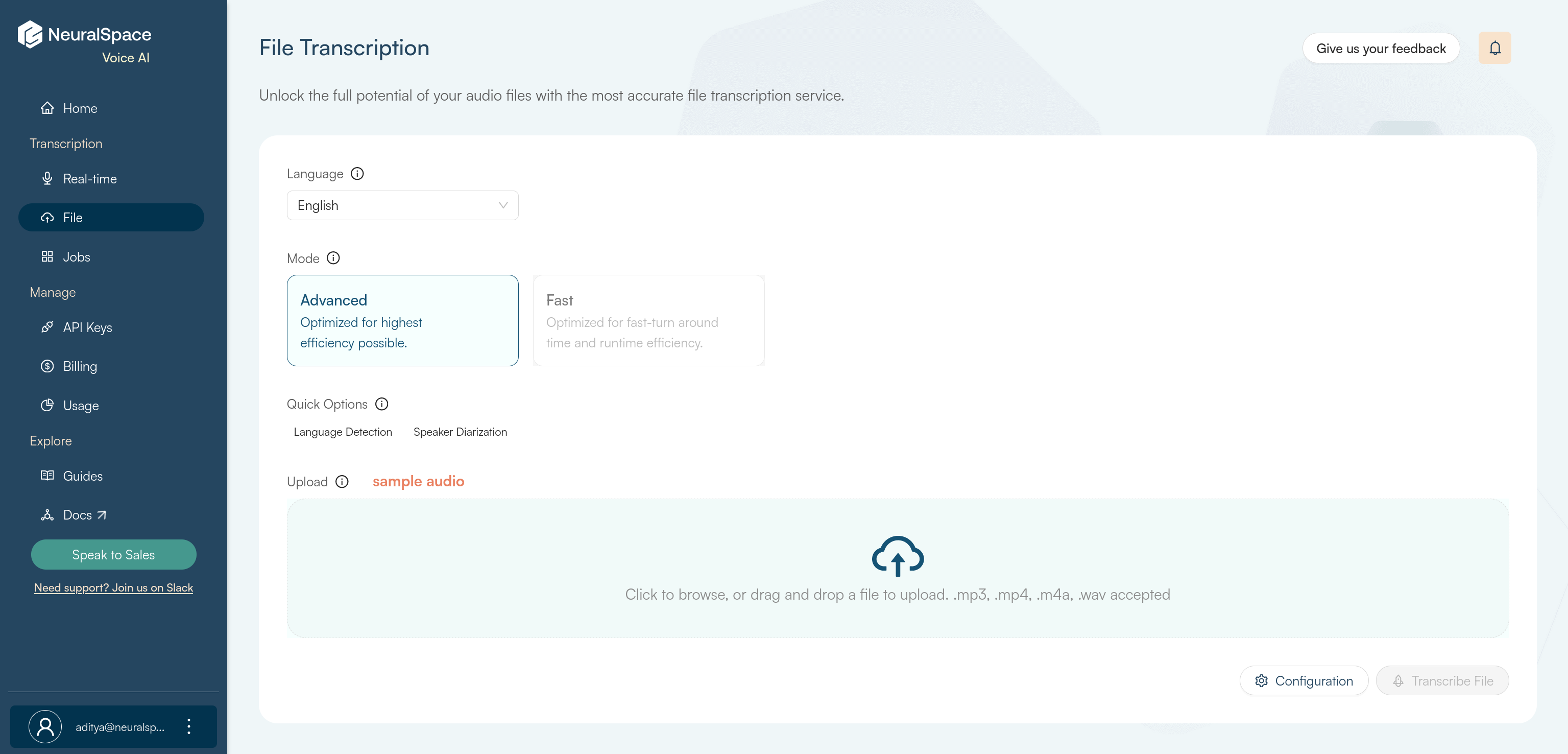
Select the language that the audio file is in from the drop-down. Select mode of transcription between the two available options - Advanced and Fast depending on your requirements.
If you want to verify the language of the audio file, you can enable the Language Detection option. And if you want the model to identify and categorize the speakers, you can enable Speaker Diarization.
Click on Language Detection and Speaker Diarization to read more about them.
If you want to obtain numbers in a normalized format in the transcript, click on the Configuration button and select Digits if all the numbers are required as digits, and Words if all of them are required as words.
This option enables you to select between having higher speed or higher accuracy.
- Fast: Our fast model is optimized for fast turnaround time and runtime efficiency.
- Advanced: Our advanced model is optimized for the best possible accuracy.
Only advanced mode is supported right now. fast will be added in the next release in December.
Below example illustrates how the transcript is formatted when each option is chosen.
| Raw Transcript | Formatted as Digits | Formatted as Words |
|---|---|---|
| I live on Street 23, and turned eighteen yesterday! | I live on Street 23, and turned 18 yesterday! | I live on Street twenty three, and turned eighteen yesterday! |
Fetch Transcription Results
- API
- Python SDK
- UI
When you pass the jobId (received in response to the transcription API) to the API below, it fetches the status and results of the job.
curl --location 'https://voice.neuralspace.ai/api/v1/jobs/{{jobId}}' \
--header 'Authorization: {{API_KEY}}'
If the status reads Completed it means the job was successful. Failed means the job could not be completed due to some reason.
Response of the request above appears as follows:
{
"success": true,
"message": "Data fetched successfully",
"data": {
"timestamp": 1692769864642,
"filename": "santa-claus-a-reading-christmas-story-17777.mp3",
"jobId": "329ff79f-a540-4536-9ef6-95a538d4d597",
"filePath": "uploads/24444581-a379-4c18-9f0b-d93336b4dddb",
"params": {
"file_transcription": {
"language_id": "en",
"mode": "advanced"
}
},
"status": "Completed",
"audioDuration": 248.328,
"progress": [
"queued",
"Started",
"transcription Started",
"transcription Completed",
"Completed"
],
"result": {
"transcription": {
"save_path": "uploads/stt-329ff79f-a540-4536-9ef6-95a538d4d597.json",
"transcript": "Towards the night before Christmas, when all through the house, not a creature was stirring. Oh, not even a mouse! The stockings were hung by the chimney with care in hopes that St. Nicholas, oh, that's me, soon would be there. The children were nestled all snug in their beds. while visions of sugar plums danced in their heads, and Mama in her kerchief, I in my cap, had just settled down for a long winter snap ... and laying his finger aside at his nose and giving a nod, the chimney he rode, his sprang to his sleigh to his steam gave a whistle, and away they all flew like the down of a thistle. But I heard him exclaim as he drove out of sight, Merry Christmas to all and to all. Good night.",
"timestamps": [
{
"word": "Towards",
"start": 1.92,
"end": 2.2,
"conf": 1
},
{
"word": "the",
"start": 2.2,
"end": 2.42,
"conf": 1
},
{
"word": "night",
"start": 2.42,
"end": 2.66,
"conf": 1
},
{
"word": "before",
"start": 2.66,
"end": 3.02,
"conf": 0.69
},
...
]
}
}
}
}
Using the jobId received in result of above request, the snippet below can be executed to fetch the status and results of the job.
# Check the job's status
# If job is complete, you will directly get the output.
result = vai.get_job_status(job_id)
print(f'Current status:\n{result}')
# This should finish in a minute for the sample audio used here.
# It will depend on the duration of the audio file and other config options.
print('Waiting for completion...')
result = vai.poll_until_complete(job_id)
print(result)
Result of the above request appears as follows
Current status:
{
"success": True,
"message": "Data fetched successfully",
"data": {
"timestamp": 1695210581508,
"filename": "english_audio_sample.mp3",
"jobId": "93e229c7-912d-43aa-9d87-96f873f69882",
"filePath": "uploads/bf377596-7a1d-4de9-82a7-9799d83f0ad9",
"params": {
"file_transcription": {
"language_id": "en",
"mode": "advanced"
}
},
"status": "Queued",
"audioDuration": 131.568,
"messsage": "",
"progress": [
"Queued"
]
}
}
Waiting for completion...
{
"success": true,
"message": "Data fetched successfully",
"data": {
"timestamp": 1695210581508,
"filename": "english_audio_sample.mp3",
"jobId": "93e229c7-912d-43aa-9d87-96f873f69882",
"params": {
"file_transcription": {
"language_id": "en",
"mode": "advanced"
}
},
"status": "Completed",
"audioDuration": 131.568,
"messsage": "",
"progress": [
"queued",
"Started",
"Transcription Started",
"Transcription Completed",
"Completed"
],
"result": {
"transcription": {
"transcript": "We've been at this for hours now. Have you found anything useful in any of those books? Not a single thing, Lewis. I'm sure that there must be something in this library. It's not like there's nothing left to be discovered. Well, I have to say that I'm tired of searching. I'm gonna take a little break. You come and cut us. I am getting a little hungry. Do you want to get someone to eat? Yeah. Food town's great right about now. What was that noise, Curtis? Did you hear that? Yes, I heard that, Lewis. I don't know, but it sounded like it came from the back of the library. Let's check it out. Okay, where you go first? Looks like a book is falling off one of the shelves. It's an old book, but it looks a bit. It's a little dusty and I can't make out what it says. Look at this, Lewis. The last treasure of Lima. Lima? Isn't that the capital city of Peru? Yes, Lewis. And it looks like there's been a treasure missing for centuries now. Look at this, Lewis. Apparently, lost treasure is located inside a temple on the outskirts of Lima. Looks like this book is a map to the treasure. Either even corn that's written down on this page. Let's get some food and plan out this next adventure. As soon as we get to Peru, I'll go straight to these coordinates that are written in the book. Great, I'll talk to you again on our land. 92, 93, 94. I'll meet at the exact location Lewis and I don't see anything. There's absolutely nothing to be seen here, just trees. Faith, look around, is there anything written on any tree? I hope this wasn't a waste of time.",
"timestamps": [
{
"word": "We've",
"start": 6.69,
"end": 7.03,
"conf": 0.99
},
{
"word": "been",
"start": 7.03,
"end": 7.09,
"conf": 0.99
},
{
"word": "at",
"start": 7.09,
"end": 7.23,
"conf": 0.99
},
{
"word": "this",
"start": 7.23,
"end": 7.37,
"conf": 0.97
},
{
"word": "for",
"start": 7.37,
"end": 7.47,
"conf": 0.97
},
{
"word": "hours",
"start": 7.47,
"end": 7.87,
"conf": 0.56
},
{
"word": "now.",
"start": 7.87,
"end": 8.43,
"conf": 1
}
...
]
}
}
}
}
To fetch your transcript, navigate to Jobs page from the side-nav. Your latest job would be at the top of the page. Click on the job name and you will be redirected to a new page where you can view your full transcript.
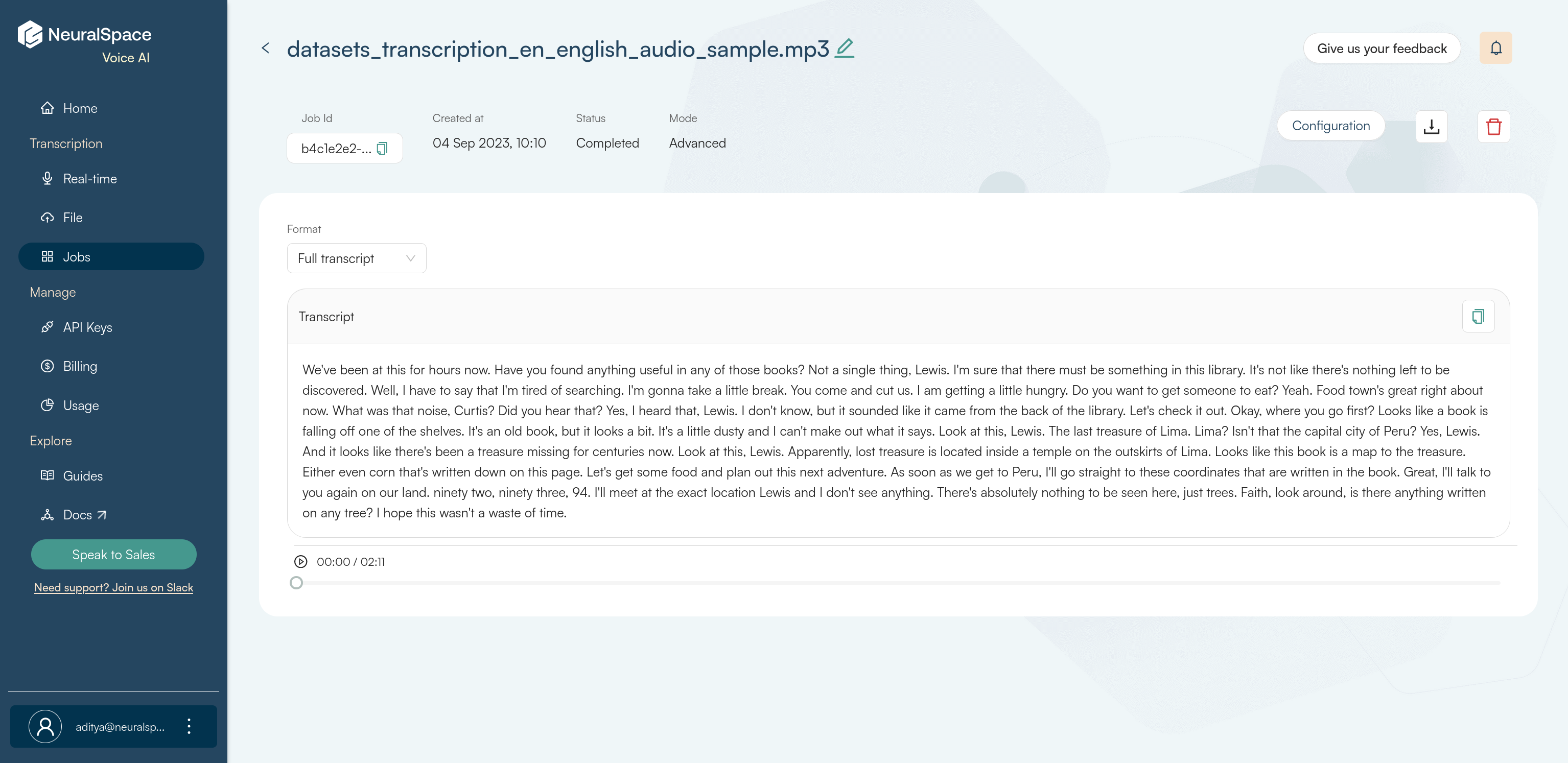
You can download the transcript in one of the following 3 formats based on your requirements:
TEXT: Plain text file with the full transcript.JSON: Json file with word-level timestamps.SRT: Subtitle file for direct use with videos.
In the results that are received as response from the API or SDK, along with the transcript, word-level timestamps are also returned by default. Timestamps are also returned if you download as JSON using the UI. This capability allows you to precisely pinpoint when each word was spoken, facilitating detailed analysis and understanding of spoken content. Refer to timestamps for more information.
Troubleshooting and FAQ
No transcript? Check out our FAQ page. If you still need help, feel free to reach out to us directly at support@neuralspace.ai or join our Slack community.